

Dr. Stone Lab · 의료 인공지능 연구노트 · 논문 리뷰
Reviewing “Foundation Models in Radiology: What, How, Why, and Why Not”
논문 | Paschali M, Chen Z, Blankemeier L, et al. Radiology, 2025;314(2):e240597
논문 유형 | Review article
이 글의 핵심 질문 | 영상의학 파운데이션 모델은 실제로 무엇을 가능하게 하며, 어떤 조건이 충족되어야 임상과 연구에서 유의미하게 활용될 수 있을지에 대한 고민
- Paper · Radiology DOI 페이지
- Preprint / Full text · arXiv 공개본
- Project / Page · Stanford AIDE Lab publication spotlight
핵심 훑어보기
- 이 논문은 특정 모델의 성능을 입증하는 원저(Original article)가 아니라, 영상의학 파운데이션 모델을 어떻게 정의할지, 어떤 데이터와 학습 전략이 요구되는지, 그리고 어떻게 평가해야 하는지를 체계적으로 정리한 리뷰 논문입니다.[1]
- 핵심 병목은 단순히 모델의 파라미터 크기에 있지 않습니다. 저자들은 3D/4D 영상, 장기 추적 자료, 다기관 데이터, 인구통계 정보, 그리고 표준화된 평가 벤치마크가 구축되지 않으면 영상의학 파운데이션 모델의 진정한 가치를 입증하기 어렵다고 분석합니다.[1]
- 활용 범위는 환자 친화적 설명, 보고서 생성, 진단 보조 등 다방면에 걸쳐 있으나, 환각(Hallucination), 자동화 편향(Automation bias), 편향성(Bias), 비용 및 환경 부담 등의 한계점이 필연적으로 수반됩니다.[1]
- Dr. Stone Lab의 관점에서 이 논문이 지니는 진정한 가치는 “영상의학에도 대형 언어 모델을 도입하자”는 단순한 주장이 아니라, 재사용 가능한 표현 학습 + 엄격히 정의된 사용 목적(Intended use) + 철저한 평가 및 감시 체계라는 현실적인 임상 번역(Clinical translation) 프레임워크를 제시했다는 점에 있습니다.
1. Introduction
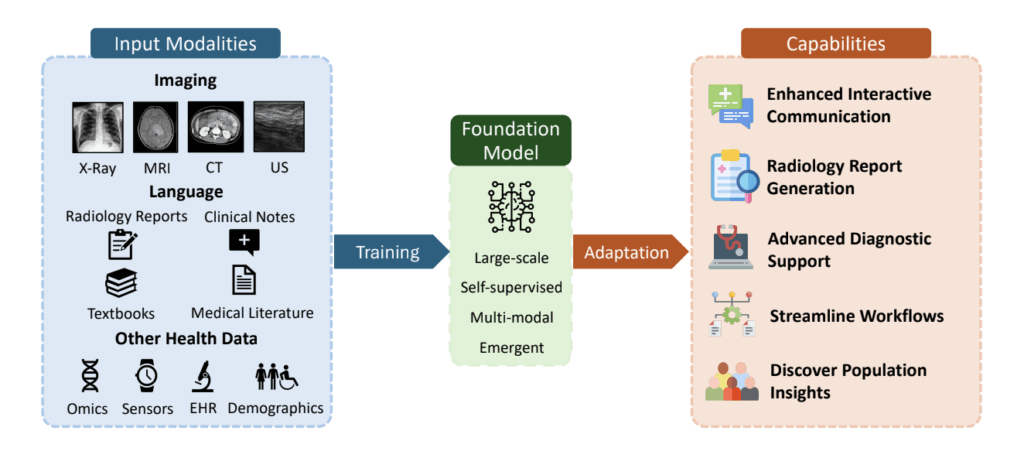
의료영상 AI는 지난 수년간 특정 과업에 최적화된 제한적 모델(Narrow AI)을 통해 상당한 성과를 도출해 왔습니다. 병변 검출, 분할, 질환 분류 등의 과제에서 높은 성능을 입증했으나, 이러한 모델은 대개 방대한 양의 전문가 라벨링을 요구하며 새로운 임상 환경으로의 전이(Transferability)가 취약하다는 한계를 지닙니다. Paschali 연구팀은 바로 이 지점에서 파운데이션 모델(Foundation Model)에 주목합니다. 대규모 비라벨 혹은 약라벨 데이터로 표현(Representation)을 선행 학습한 후 다양한 임상 과제로 적응시키는 방식이 영상의학 분야에서도 매우 유의미할 수 있다고 제언합니다.[1]
여기서 주목할 점은, 저자들이 파운데이션 모델을 맹목적인 기술적 유행으로 취급하지 않았다는 사실입니다. 본 리뷰는 영상의학 영역에서 파운데이션 모델을 무엇으로 정의할 것인지, 어떠한 데이터가 필수적인지, 어떻게 학습 및 적응시킬 것인지, 그리고 무엇보다 어떻게 객관적으로 평가할 것인지를 통합적으로 고찰하려는 학술적 시도입니다. 학계와 산업계, 규제 당국이 모두 파운데이션 모델에 주목하는 현시점에서, 이 논문이 제시하는 프레임워크는 단순한 요약본을 넘어 향후 연구 계획의 탄탄한 골격에 가깝습니다.
이 리뷰는 “영상의학에도 대규모 모델이 도입된다”는 선언적 의미를 넘어섭니다. 무엇을 파운데이션 모델이라 명명할지부터, 데이터 요구사항, 적응 방법론, 인간 중심의 평가(Human evaluation), 하위 그룹 분석(Subgroup analysis), 배치 후 모니터링(Deployment monitoring)까지의 전 주기를 유기적으로 연결하여 설명합니다. 연구자의 입장에서는 단순히 높은 리더보드 점수보다 ‘무엇을 검증해야만 실제 임상 현장으로 번역 가능한 연구가 되는가’를 묻는 중요한 이정표 역할을 합니다.
2. 영상의학 파운데이션 모델은 무엇이 다른가
2-1. 파운데이션 모델의 네 가지 핵심 속성
저자들은 영상의 파운데이션 모델을 제대로 이해하기 위해 다음의 네 가지 속성을 통합적으로 고려해야 한다고 정리합니다. 첫째, 모델의 아키텍처와 데이터의 규모가 충분히 뒷받침되어야 합니다. 둘째, 이미지와 텍스트를 넘어 전자의무기록(EHR) 등 다양한 임상 정보를 아우르는 멀티모달성(Multimodality)이 확보되어야 합니다. 셋째, 정답 라벨 없이도 데이터의 내재적 구조를 파악하는 자기지도학습(Self-supervised learning)이 필수적입니다. 넷째, 당초 학습 목표로 명시되지 않았음에도 모델 규모 확장에 따라 자발적으로 발현되는 발현적 능력(Emergent capability)이 관찰될 수 있어야 합니다.[1]
2-2. 기존의 제한적 AI(Narrow AI)와의 차이점
| 비교 항목 | 기존 Task-specific AI | Foundation Model 접근법 |
|---|---|---|
| 학습 데이터 | 전문가 라벨 중심의 데이터 | 대규모 비라벨/약라벨 및 멀티모달 데이터 |
| 연구 목표 | 단일 과업에 대한 성능 최적화 | 범용적 표현 학습 후 다양한 하위 과업에 적응 |
| 주요 장점 | 특정 과업 내에서 최고 성능(SOTA) 달성 용이 | 높은 재사용성, 확장성 및 유연한 적응성 |
| 내재적 약점 | 새로운 과업 및 환경으로의 전이가 매우 제한적임 | 평가 체계의 복잡성, 환각 현상, 고비용 및 임상 배치 리스크 |
Stanford AIDE Lab과의 인터뷰에서 저자들은 파운데이션 모델이 지닌 잠재력에도 불구하고, 단일 과업에 특화된 AI가 완전히 도태되는 것은 아니며 특정 임상 환경에서는 오히려 Task-specific 모델이 더 효율적일 수 있다고 분명하게 강조합니다. 즉, 미래의 의료 AI 생태계는 거대한 단일 모델이 모든 것을 대체하기보다는, 다양한 스케일의 모델들이 임상 데이터 흐름 속에서 유기적으로 상호작용하는 계층적 구조에 가까울 것으로 전망됩니다.
- Self-supervised learning (자기지도학습) · 명시적인 정답 라벨 없이, 데이터 자체가 지닌 내재적 구조와 패턴을 이용하여 범용적 표현을 학습하는 기법
- Emergent capability (발현적 능력) · 설계 단계에서 의도하거나 직접적으로 학습시키지 않았음에도, 모델의 규모(파라미터, 데이터)가 임계점을 넘어서면서 자발적으로 나타나는 일반화 및 추론 능력
- Multimodal (멀티모달) · 의료 영상(CT, MRI 등)과 텍스트(판독문)뿐만 아니라, 전자의무기록(EHR), 혈액 검사 수치, 인구통계학적 정보 등 서로 다른 형태의 임상 데이터를 통합적으로 처리하는 접근법
- Intended use (사용 목적) · 실제 의료기기 소프트웨어(SaMD)나 AI 시스템이 정확히 누구를 대상으로, 어떠한 임상적 상황에서, 어떤 형태의 의사결정을 보조하도록 설계되었는지를 명시하는 규제과학적 핵심 개념
3. 데이터와 학습: 무엇으로 어떻게 학습하는가
3-1. 공개 데이터셋의 현주소와 한계
본 리뷰는 영상의학 파운데이션 모델의 성공 여부를 궁극적으로 데이터의 양과 질의 문제로 환원하여 설명합니다. Vision 도메인에서는 RadImageNet과 같은 100만 장 규모의 CT/MRI 데이터셋이 소개되며, Vision-Language 도메인에서는 30만 쌍 이상의 흉부 X-ray와 판독문(Image-report pair)을 보유한 MIMIC-CXR이 대표적인 자원으로 언급됩니다. 그러나 저자들은 단순히 “데이터의 양이 방대하다”는 사실만으로는 결코 충분하지 않으며, 임상적 맥락을 정확히 담고 있는 고품질의 텍스트와 영상이 쌍을 이루는 구조(Paired structure)가 필수적이라고 강하게 경고합니다. 웹 크롤링 기반의 정제되지 않은 데이터는 모델이 부정확한 의학적 지식을 학습하게 만드는 치명적인 원인이 될 수 있습니다.[1]
| 데이터 축(Axis) | 논문에서 제시된 현재의 주요 자원 | 임상 번역을 위해 향후 확충되어야 할 과제 |
|---|---|---|
| Vision | RadImageNet (100만+), MIMIC-CXR 등 수십만 장 규모의 흉부 X-ray | 3D/4D CT 및 MRI, 초음파 영상, 그리고 더욱 세분화된 다양한 해부학적 영역의 데이터 |
| Vision-Language | MIMIC-CXR (30만+ 쌍), PubMed 추출 이미지-캡션 (100만+ 쌍) | 전문의가 직접 검수한 고품질의 판독문 기반 쌍(Paired) 데이터 및 다기관(Multi-center) 획득 자료 |
| Segmentation | 수백만 장 규모의 Image-mask 오픈소스 자원 | 희귀 질환(Rare conditions), 환자의 장기 추적 관찰 자료, 다양한 장비 및 제조사 간의 도메인 차이(Domain shift)가 반영된 데이터 |
3-2. 사전 학습(Pre-training) 전략: 생성형 vs 대조학습
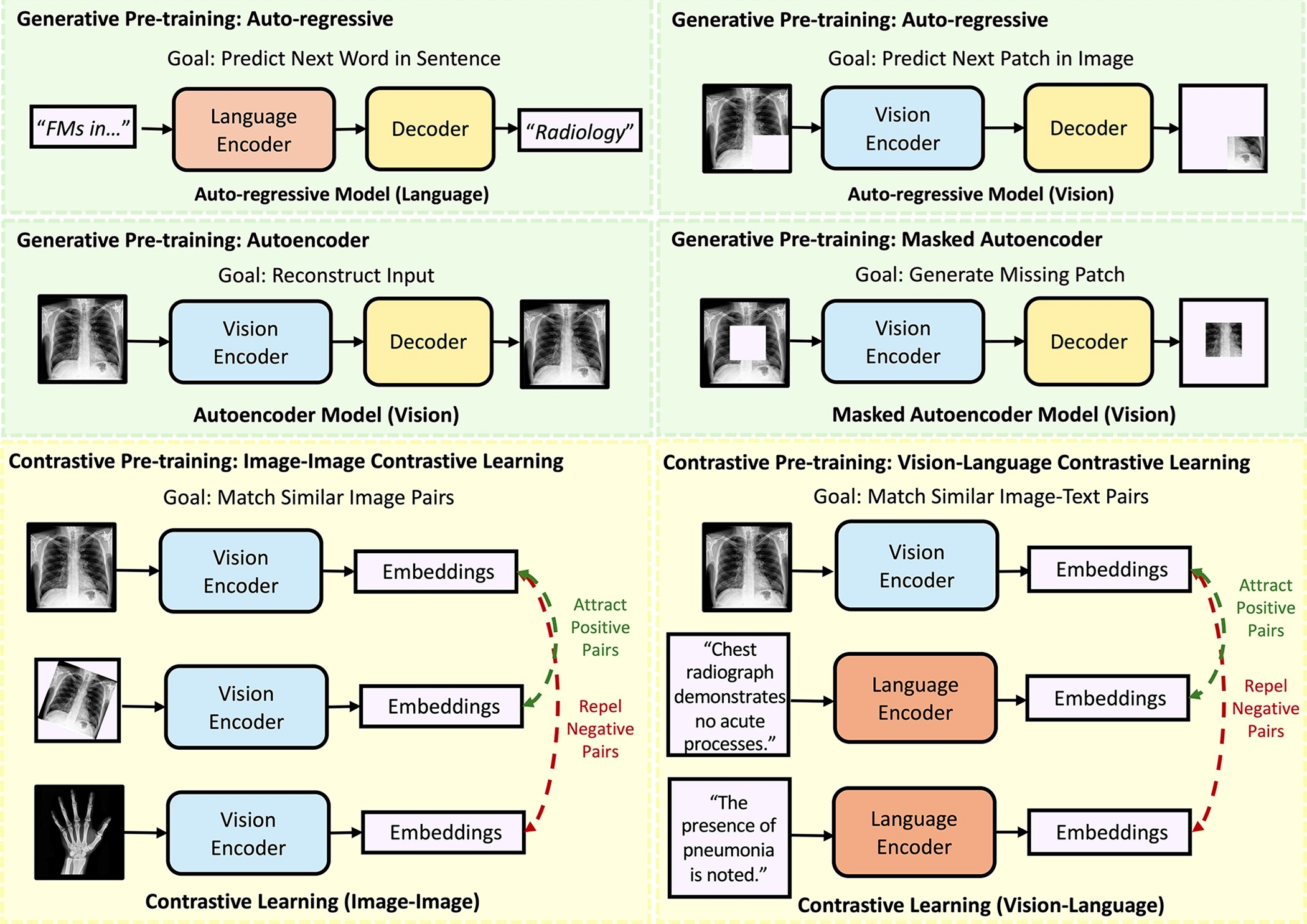
상단 패널은 자기회귀(Auto-regressive) 및 마스크드 오토인코더(Masked Autoencoder) 구조를 활용한 생성형 학습 모델을 보여주며, 하단 패널은 이미지-이미지(Image-Image) 및 비전-언어(Vision-Language) 간의 의미 공간을 정렬하는 대조학습(Contrastive Learning) 모델의 아키텍처와 학습 목표(Positive pair 당기기, Negative pair 밀어내기)를 설명합니다. (Figure from Paschali et al.)
영상의 파운데이션 모델의 인코더(Encoder) 학습 방법론은 크게 생성형(Generative) 접근법과 대조학습(Contrastive) 접근법으로 대별됩니다. 생성형 모델(예: Masked Autoencoders, MAE)은 의도적으로 가려진 의료 영상의 패치나 텍스트 토큰을 모델 스스로 복원하도록 강제함으로써, 데이터의 기저 분포와 구조적 특성을 심층적으로 이해하도록 유도합니다. 반면, 대조학습 모델(예: CLIP 기반 아키텍처)은 동일 환자의 다른 검사 영상(View)이나 이미지-판독문 쌍(Positive pair)을 잠재 공간(Latent space) 내에서 가깝게 위치시키고, 무관한 쌍은 멀어지도록 학습하여 시각 정보와 언어 정보 간의 강력한 의미론적 정렬(Semantic alignment)을 구현합니다.[1]
3-3. 연구계가 당면한 차세대 데이터셋의 요건
본 리뷰에서 임상 현장의 연구자들에게 가장 묵직한 메시지를 던지는 부분은 바로 차세대 데이터셋의 구축 방향입니다. 현재 우리에게 필요한 것은 단순히 수백만 장의 흉부 X-ray 데이터를 추가로 수집하는 것이 아닙니다. 시계열적 변화(Temporal change)를 추적할 수 있는 종단적(Longitudinal) 데이터, 병원 시스템 간의 차이(Site shift)를 극복하기 위한 다기관(Multi-site) 데이터, 그리고 인공지능의 공정성(Fairness)을 검증할 수 있는 상세한 인구통계학적 정보가 결합된 다차원적 데이터셋의 구축이 시급히 요구됩니다.
4. 적응과 평가: 연구 결과는 어떻게 해석되어야 하는가
이 논문은 특정 연구팀의 새로운 파운데이션 모델 아키텍처를 제안하거나 벤치마크 리더보드 순위를 나열하는 원저가 아닙니다. 따라서 본 리뷰에서 논의되는 “실험과 평가”는 단순한 정량적 성능 지표의 비교가 아니라, ‘모델의 임상적 안전성과 유효성을 입증하기 위해 어떠한 평가 축(Evaluation axes)을 설계해야 하는가’에 대한 방법론적 가이드라인으로 해석되어야 합니다.
4-1. 모델 적응(Adaptation) 전략의 분류
| 적응 방법론 (Adaptation) | 파라미터 업데이트 범위 | 주요 활용 목적 및 장점 |
|---|---|---|
| Zero-shot / Few-shot | 가중치 업데이트 사실상 없음 (Frozen) | 레이블링된 학습 데이터가 극도로 부족한 초기 탐색 단계나 희귀 질환 환경에서 신속한 성능 평가 |
| Linear Probing | 사전 학습된 인코더는 고정(Frozen)하고, 최상단의 분류기(Classifier Head)만 학습 | 대규모 모델의 컴퓨팅 리소스를 크게 절감하면서도, 사전 학습된 표현 공간의 유효성을 검증 |
| Fine-tuning | 인코더와 분류기를 포함한 전체 혹은 상당 부분의 파라미터 업데이트 | 특정 하위 과업(Downstream task)에 대한 모델의 성능을 극대화하고자 할 때 적용 |
| Instruction Tuning | 자연어 지시문(Instruction)과 응답 데이터셋을 기반으로 한 모델 미세조정 | 영상의학 판독문 생성, 복잡한 임상 질의응답(VQA) 등 인간 친화적인 멀티태스크 수행 능력 확보 |
4-2. 인간 중심 평가(Human Evaluation)의 불가결성
생성적 과업(Generative tasks), 특히 영상의학 판독문 생성 모델을 평가함에 있어서 단순히 BLEU나 ROUGE와 같은 텍스트 유사도 지표에 의존하는 것은 매우 위험합니다. 생성된 문장의 유창성이 의학적 정확성을 결코 담보하지 않기 때문입니다. 모델이 생성한 판독문은 참조(Reference) 정답과 형태적으로 다르더라도 임상적으로 완전히 타당할 수 있으며, 반대로 유려한 문장 속에 결정적인 병변에 대한 누락이나 환각(Hallucination)이 숨어있을 수 있습니다. 따라서 전문의가 직접 개입하여 임상적 완전성(Completeness), 간결성(Conciseness), 그리고 정확성(Correctness)을 다각도로 평가하는 인간 중심 평가(Human Evaluation) 체계의 구축이 파운데이션 모델 연구의 필수적인 요건으로 강조됩니다.[1]
- 무엇을 평가하도록 설계하였는가? 단순 분류를 넘어 세분화된 진단, 시각적 질의응답(VQA), 임상 보고서 생성 등 모델의 다중 능력을 복합적으로 검증하고 있는가?
- 어떠한 축을 기준으로 비교하였는가? 전체 데이터셋에 대한 평균 성능에 매몰되지 않고, 성별/인종/연령 등에 따른 하위 그룹 성능(Subgroup performance)의 편차를 분석하였는가?
- 결과를 어떻게 임상적으로 해석해야 하는가? 매끄러운 텍스트 생성 결과물이나 인상적인 데모 시연이 곧 임상 현장에서의 신뢰성과 직결되는 것은 아님을 명확히 인지하고 있는가?
- 이 모델이 아직 입증하지 못한 영역은 어디인가? 장기적인 시계열 추적, 정밀한 해부학적 정량화, 그리고 외부 다기관 데이터에서의 일관된 일반화 능력이 충분히 검증되었는가?
5. 임상 적용 가능성과 현재의 한계
5-1. 실전 도입이 기대되는 영역
- 환자-의사 간 커뮤니케이션 증진: 고도로 전문화된 영상의학 판독문을 일반 환자도 쉽게 이해할 수 있는 평이한 언어로 변환(Translation)하여 의료진과 환자 간의 정보 비대칭성을 해소하고 소통을 강화합니다. (단, 비전문가인 환자의 과신 리스크에 대한 철저한 대비가 수반되어야 합니다.)
- 의료진 워크플로 최적화 보조: 응급실 환경에서 긴급한 조치가 필요한 소견을 식별하여 영상의학 전문의의 판독 우선순위(Triage queue)를 재조정하거나, 판독문 초안(Draft) 자동 생성, 누락 방지를 위한 품질 관리(Quality control) 등 의료진의 최종 의사결정을 ‘대체’하지 않고 ‘보조’하는 영역에서 단기적인 적용 가능성이 높게 평가됩니다.
5-2. 여전히 극복해야 할 학술적 난제
초기 파운데이션 모델들이 보여준 놀라운 자연어 처리 및 기본 영상 인식 능력에도 불구하고, 종양의 크기 변화나 침윤 정도를 밀리미터 단위로 정밀하게 계측하는 정량적 분석(Quantitative analysis), 동일 환자의 수개월 혹은 수년에 걸친 과거 영상들을 종합하여 미세한 질병의 진행 여부를 추론하는 시계열적 판단, 그리고 상이한 제조사의 장비가 혼재된 다기관 임상 환경에서의 강건한 성능 유지는 현시점의 파운데이션 모델이 온전히 정복하지 못한 핵심 과제로 남아있습니다.
6. 도입 전 반드시 점검해야 할 위험 요소 (The “Why Not”)
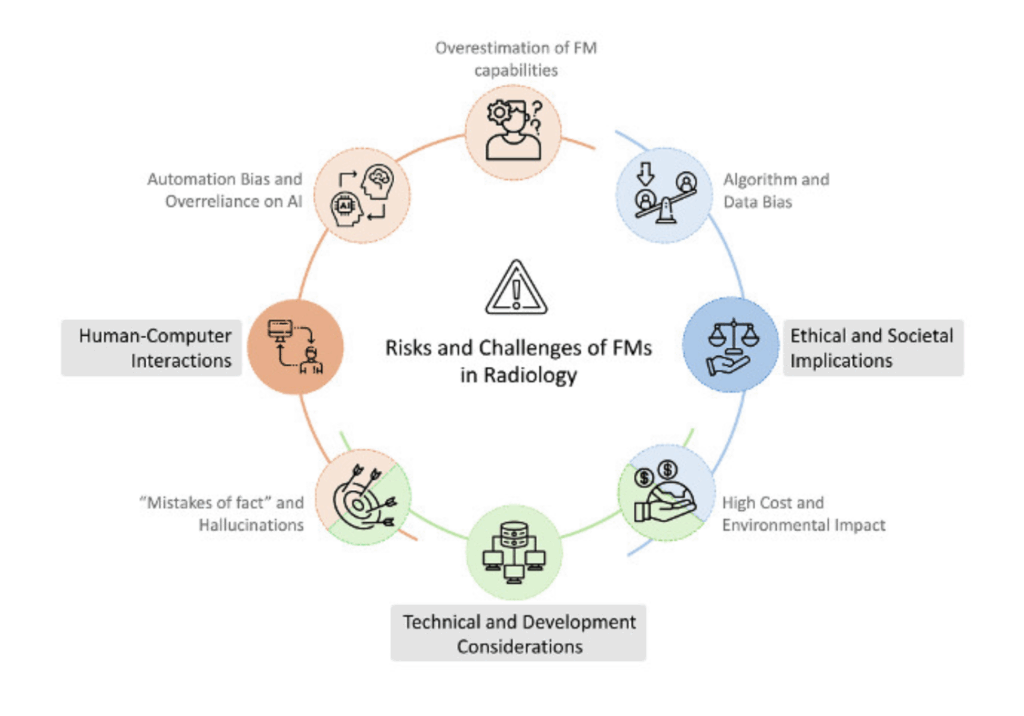
기술 및 개발 측면의 사실 오류(환각 현상)와 환경적·경제적 고비용 문제, 인간-컴퓨터 상호작용 측면의 자동화 편향(Automation Bias) 및 과신, 그리고 윤리 및 사회적 측면의 알고리즘 편향성 등을 다각도로 분류하여 제시하고 있습니다. (Figure from Paschali et al.)
6-1. 규제과학 관점의 실전 도입 체크리스트 (TPLC 접근법)
☐ 모델의 사용 목적(Intended Use)과 대상 환자군이 임상적으로 구체적이고 좁게 정의되어 문서화되었습니까?
☐ 개발에 사용되지 않은 외부 다기관 데이터를 활용한 검증 및 인구통계학적 하위 그룹 분석(Subgroup analysis)이 투명하게 공개되었습니까?
☐ 모델이 생성한 텍스트나 예측 결과에 대해 환각(Hallucination) 및 사실 오류 여부를 체계적으로 모니터링하는 전문가 리뷰 프로세스가 존재합니까?
☐ 해당 AI 시스템이 ‘무엇을 자동화할 수 있고’, 반대로 ‘어떤 상황에서 한계를 지니는지’ 의료진과 환자에게 명확히 고지(Transparency)되고 있습니까?
☐ 임상 현장 배치 이후 발생할 수 있는 데이터 분포의 변화(Data drift)를 지속적으로 추적하고 모델을 업데이트하기 위한 사후 관리 계획(Post-deployment monitoring)이 수립되어 있습니까?
☐ 전체 제품 수명 주기(Total Product Life Cycle, TPLC) 및 우수 기계학습 실무 가이드라인(GMLP)에 입각하여 시스템이 설계되고 관리되고 있습니까?
6-2. 자동화 편향(Automation Bias) 및 데이터 편향성 문제
영상의학 파운데이션 모델이 겉보기에 완벽한 판독문을 생성해내며 의료진의 신뢰를 얻기 시작할 때, 역설적으로 가장 큰 위험이 발생합니다. 이는 인간이 AI의 결과물을 무비판적으로 수용하게 되는 자동화 편향(Automation bias)입니다. 모델이 산출한 유창한 문장이 곧 의학적 사실성(Factuality)을 보장하는 것은 절대 아니므로, 이에 대한 엄격한 방어 기제(Safeguards) 설계가 기술 자체의 개발만큼이나 중요하게 다뤄져야 합니다. 또한, 기존 의료 AI에서 지속적으로 제기되어 온 학습 데이터의 불균형으로 인한 인종, 성별 등에 대한 알고리즘 편향성(Bias) 문제와 대형 모델 운용에 수반되는 천문학적인 컴퓨팅 비용(Cost) 및 환경적 영향 또한 도입 전 심도 있게 논의되어야 할 과제입니다.[1]
객관적 사실: 이 논문은 영상의학 파운데이션 모델의 입력 데이터 조건부터 학습 방법론, 적응 기법, 임상적 평가 지표, 그리고 내재된 위험 요소까지 매우 균형 잡힌 시각으로 정리한 훌륭한 리뷰 문헌입니다.
연구자적 해석: 본 리뷰가 전하고자 하는 진정한 학술적 메시지는 단순히 “의료 영상 분야에도 최신 거대 언어 모델을 접목하자”는 유행의 추종이 아닙니다. 신뢰할 수 있는 영상의학 파운데이션 모델이란, 뛰어난 단일 아키텍처 하나가 아니라 편향 없는 데이터 설계, 인간 중심의 철저한 평가 체계, 명확한 사용 경계선의 설정, 그리고 배치 후의 지속적 감시 체계를 모두 아우르는 총체적 시스템(Holistic system)이어야 한다는 점을 강력히 시사합니다.
임상 적용에 대한 전망: 가까운 미래의 의료 현장에서는 만능형 단일 파운데이션 모델(Generalist FM)이 모든 업무를 단독으로 처리하기보다는, 특정 세부 질환에 고도로 최적화된 기존의 Task-specific AI와 파운데이션 모델이 워크플로 내에서 유기적으로 협력하는 하이브리드 및 계층적 구조가 훨씬 더 현실적이고 안전한 접근 방식일 것으로 판단됩니다.[3]
7. 결론: 이 논문을 어떻게 해석하고 활용할 것인가
본 리뷰 논문이 지니는 가장 큰 학술적 의의는, ‘영상의학 파운데이션 모델’이라는 모호한 기술적 유행어를 엄밀하고 검증 가능한 ‘연구 및 규제 프레임워크’의 언어로 전환해 내었다는 점에 있습니다. 멀티모달 데이터에 기반한 범용적 표현 학습, 좁고 명확하게 정의된 사용 목적(Intended use), 인간 전문가의 개입이 필수적인 평가 프로토콜, 소수 집단에 대한 하위 분석, 그리고 임상 배치 이후의 지속적 모니터링 계획까지 유기적으로 통합되지 않는다면, 어떠한 첨단 파운데이션 모델이라 할지라도 임상 현장으로의 진정한 번역(Translation)을 이뤄내지 못한 채 일회성 데모(Demo) 수준에 머물게 될 것입니다.[1]
결론적으로, 이 논문은 첨단 인공지능 기술에 대한 맹목적 낙관론을 유포하기보다는, 그 낙관이 현실화되기 위해 충족되어야 할 엄격한 조건들을 체계적으로 구체화하고 있습니다. AI 개발 연구자에게는 향후 데이터 구축 및 벤치마크 설계의 올바른 이정표를, 실제 기술을 활용할 임상의에게는 과신이 불러올 수 있는 잠재적 위험의 경계선을, 그리고 상용화를 추진하는 제품 개발팀에게는 제품 수명 주기 관리(TPLC) 및 투명성(Transparency) 문서화의 절대적 중요성을 다시금 깊이 상기시키는 필수적인 문헌이라 평가할 수 있습니다.[4][5]
참고자료 / 출처
- Paschali M, Chen Z, Blankemeier L, et al. Foundation Models in Radiology: What, How, Why, and Why Not. Radiology. 2025;314(2):e240597. DOI 공식 페이지
- Paschali M, Chen Z, Blankemeier L, et al. Foundation Models in Radiology: What, How, When, Why and Why Not. arXiv preprint, 2024. arXiv 사전 공개본
- Stanford AIDE Lab. Foundation Models in Radiology: What, How, Why, and Why Not? publication spotlight. 인터뷰 및 해설 읽기
- U.S. FDA. Artificial Intelligence-Enabled Device Software Functions: Lifecycle Management and Marketing Submission Recommendations. FDA 가이드라인 페이지
- U.S. FDA. Transparency for Machine Learning-Enabled Medical Devices: Guiding Principles. FDA 투명성 원칙 페이지
- U.S. FDA / IMDRF. Good Machine Learning Practice for Medical Device Development: Guiding Principles. GMLP 가이드라인 페이지
- Lekadir K, Frangi AF, Porras AR, et al. FUTURE-AI: international consensus guideline for trustworthy and deployable artificial intelligence in healthcare. BMJ. 2025. BMJ 논문 페이지